-

Want a paper copy?
You can now buy the book!
All royalties go to the Cystic Fibrosis Trust.Spotted an error? Have comments?
Let us know!Get hands on with source code for the book.
1.2 Updating our beliefs
Searching carefully around the library, Dr Bayes spots a bullet lodged in the book case. “Hmm, interesting”, she says, “I think this could be an important clue”.

So it seems that the murder weapon was the revolver, not the dagger. Our intuition is that this new evidence points more strongly towards Major Grey than it does to Miss Auburn, since the Major, due to his age and military background, is more likely to have experience with a revolver than Miss Auburn. But how can we use this information?
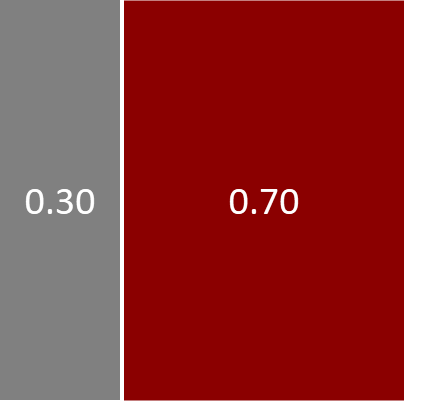
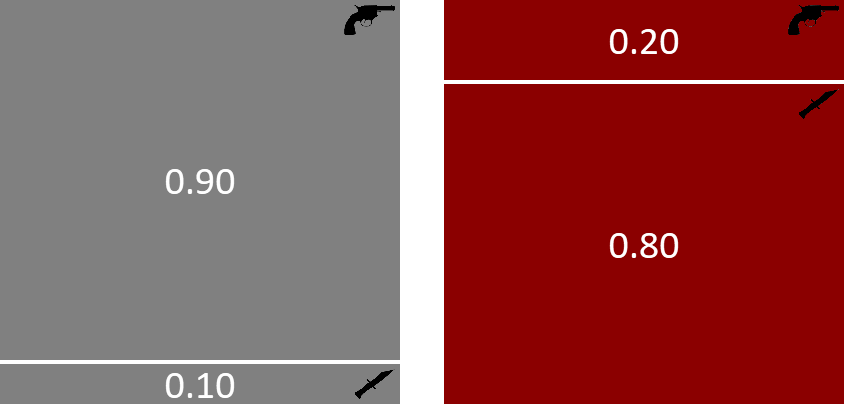
A convenient way to think about the probabilities we have looked at so far is as a description of the process by which we believe the murder took place, taking account of the various sources of uncertainty. So, in this process, we first pick the murderer with the help of Figure 1.2. This shows that there is a 30% chance of choosing Major Grey and a 70% chance of choosing Miss Auburn. Let us suppose that Miss Auburn was the murderer. We can then refer to Figure 1.4 to pick which weapon she used. There is a 20% chance that she would have used the revolver and an 80% chance that she would have used the dagger. Let’s consider the event of Miss Auburn picking the revolver. The probability of choosing Miss Auburn and the revolver is therefore 70% 20% = 14%. This is the joint probability of choosing Auburn and revolver. If we repeat this exercise for the other three combinations of murderer and weapon we obtain the joint probability distribution over the two random variables, which we can illustrate pictorially as seen in Figure 1.5.
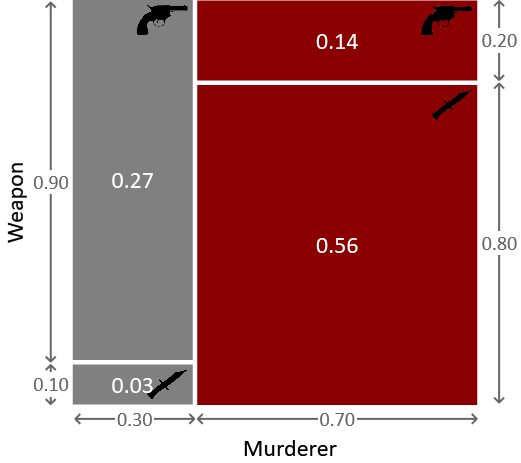
Figure 1.6 below shows how this joint distribution was constructed from the previous distributions we have defined. We have taken the left-hand slice of the square corresponding to Major Grey, and divided it vertically in proportion to the two regions of the conditional probability square for Grey. Likewise, we have taken the right-hand slice of the square corresponding Miss Auburn, and divided it vertically in proportion to the two regions of the conditional probability square for Auburn.
We denote this joint probability distribution by , which should be read as “the probability of weapon and murderer”. In general, the joint distribution of two random variables A and B can be written and specifies the probability for each possible combination of settings of A and B. Because probabilities must sum to one, we have
Here the notation denotes a sum over all possible states of the random variable A, and likewise for B. This corresponds to the total area of the square in Figure 1.5 being 1, and arises because we assume the world consists of one, and only one, combination of murderer and weapon. Picking a point randomly in this new square corresponds to sampling from the joint probability distribution.
Two rules for working with joint probabilities
We’d like to use our joint probability distribution to update our beliefs about who committed the murder, in the light of this compelling new evidence. To do this, we need to introduce two important rules for working with joint distributions.
From the discussion above, we see that our joint probability distribution is obtained by taking the probability distribution over murderer and multiplying by the conditional distribution of weapon. This can be written in the form
Equation (1.15) is an example of a very important result called the product rule of probability. The product rule says that the joint distribution of A and B can be written as the product of the distribution over A and the conditional distribution of B conditioned on the value of A, in the form
Now suppose we sum up the values in the two left-hand regions of Figure 1.5 corresponding to Major Grey. Their total area is 0.3, as we expect because we know that the probability of Grey being the murderer is 0.3. The sum is over the different possibilities for the choice of weapon, so we can express this in the form
Similarly, the entries in the second column, corresponding to the murderer being Miss Auburn, must add up to 0.7. Combining these together we can write
This is an example of the sum rule of probability, which says that the probability distribution over a random variable A is obtained by summing the joint distribution over all values of B
In this context, the distribution is known as the marginal distribution for A and the act of summing out B is called marginalisation. We can equally apply the sum rule to marginalise over the murderer to find the probability that each of the weapons was used, irrespective of who used them. If we sum the areas of the top two regions of Figure 1.5 we see that the probability of the weapon being the revolver was , or 41%. Similarly, if we add up the areas of the bottom two regions we see that the probability that the weapon was the dagger is or 59%. The two marginal probabilities then add up to , which we expect since the weapon must have been either the revolver or the dagger.
The sum and product rules are very general. They apply not just when A and B are binary random variables, but also when they are multi-state random variables, and even when they are continuous (in which case the sums are replaced by integrations). Furthermore, A and B could each represent sets of several random variables. For example, if , then from the product rule (1.16) we have
and similarly the sum rule (1.19) gives
The last result is particularly useful since it shows that we can find the marginal distribution for a particular random variable in a joint distribution by summing over all the other random variables, no matter how many there are.
Together, the product rule and sum rule provide the two key results that we will need throughout the book in order to manipulate and calculate probabilities. It is remarkable that the rich and powerful complexity of probabilistic reasoning is all founded on these two simple rules.
Inference using the joint distribution
We now have the tools that we need to incorporate the fact that the weapon was the revolver. Intuitively, we expect that this should increase the probability that Grey was the murderer but to confirm this we need to calculate that updated probability. The process of computing revised probability distributions after we have observed the values of some of the random variables, is called probabilistic inference. Inference is the cornerstone of model-based machine learning – it can be used for reasoning about a situation, learning from data, making predictions – in fact any machine learning task can be achieved using inference.
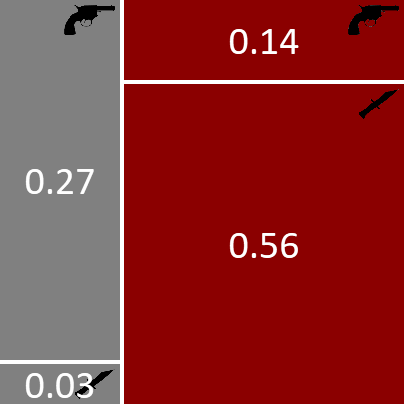
We can do inference using the joint probability distribution shown in Figure 1.5. Before we observe which weapon was used to commit the crime, all points within this square are equally likely. Now that we know the weapon was the revolver, we can rule out the two lower regions corresponding to the weapon being the dagger, as illustrated in Figure 1.7.
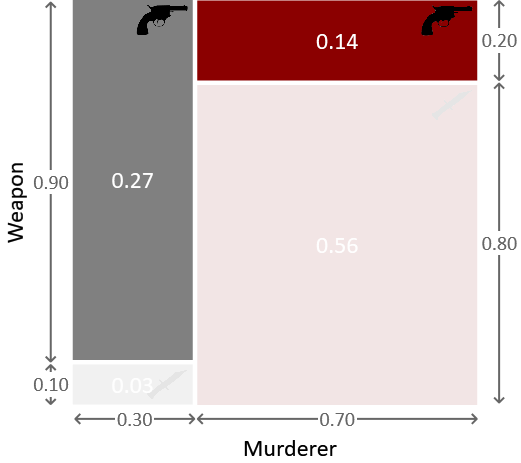
Because all points in the remaining two regions are equally likely, we see that the probability of the murderer being Major Grey is given by the fraction of the remaining area given by the grey box on the left. in other words a 66% probability. This is significantly higher than the 30% probability we had before observing that the weapon used was the revolver. We see that our intuition is therefore correct and it now looks more likely that Grey is the murderer rather than Auburn. The probability that we assigned to Grey being the murderer before seeing the evidence of the bullet is sometimes called the prior probability (or just the prior), while the revised probability after seeing the new evidence is called the posterior probability (or just the posterior).
The probability that Miss Auburn is the murderer is similarly given by Because the murderer is either Grey or Auburn these two probabilities again sum to 1. We can capture this pictorially by re-scaling the regions in Figure 1.7 to give the diagram shown in Figure 1.8.
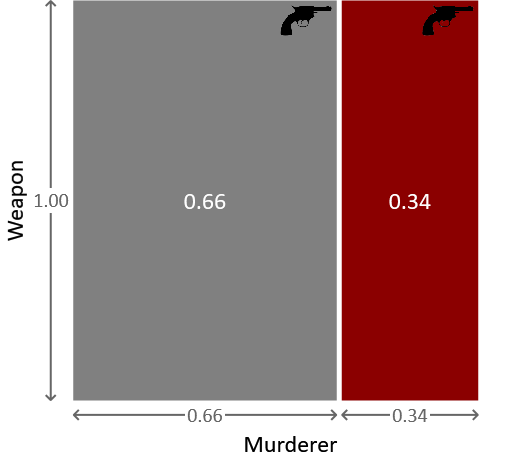
We have seen that, as new data, or evidence, is collected we can use the product and sum rules to revise the probabilities to reflect changing levels of uncertainty. The system can be viewed as having learned from that data.

So, after all this hard work, have we finally solved our murder mystery? Well, given the evidence so far it appears that Grey is more likely to be the murderer, but the probability of his guilt currently stands at 66% which feels too small for a conviction. But how high a probability would we need? To find an answer we turn to William Blackstone’s principle [Blackstone, 1765]:
“Better that ten guilty persons escape than one innocent suffer.”
We therefore need a probability of guilt for our murderer which exceeds . To achieve this level of proof we will need to gather more evidence from the crime scene, and to make a corresponding extension to our joint probability in order to incorporate this new evidence. We’ll look at how to do this in the next section.
joint probabilityA probability distribution over multiple variables which gives the probability of the variables jointly taking a particular configuration of values. For example, is a joint distribution over the random variables A, B, and C.
product rule of probabilityThe rule that the joint distribution of A and B can be written as the product of the distribution over A and the conditional distribution of B conditioned on the value of A, in the form
sum rule of probabilityThe rule that the probability distribution over a random variable A is obtained by summing the joint distribution over all values of B
marginal distributionThe distribution over a random variable computed by using the sum rule to sum a joint distribution over all other variables in the distribution.
marginalisationThe process of summing a joint distribution to compute a marginal distribution.
probabilistic inferenceThe process of computing probability distributions over certain specified random variables, usually after observing the value of other random variables.
prior probabilityThe probability distribution over a random variable before seeing any data. Careful choice of prior distributions is an important part of model design.
posterior probabilityThe updated probability distribution over a random variable after some data has been taken into account. The aim of inference is to compute posterior probability distributions over variables of interest.
The following exercises will help embed the concepts you have learned in this section. It may help to refer back to the text or to the concept summary below.
- Check for yourself that the joint probabilities for the four areas in Figure 1.5 are correct and confirm that their total is 1. Use this figure to compute the posterior probability over murderer, if the murder weapon had been the dagger rather than the revolver.
- Choose one of the following scenarios (continued from the previous self assessment) or choose your own scenario
- Whether you are late for work, depending on whether or not traffic is bad.
- Whether a user replies to an email, depending on whether or not he knows the sender.
- Whether it will rain on a particular day, depending on whether or not it rained on the previous day.
- Now assume that you know the value of the conditioned variable, for example, assume that you are late for work on a particular day. Now compute the posterior probability of the conditioning variable, for example, the probability that the traffic was bad on that day. You can achieve this using your diagram from the previous question, by crossing out the areas that don’t apply and finding the fraction of the remaining area where the conditioning event happened.
- For your joint probability distribution, write a program to print out 1,000 joint samples of both variables. Compute the fraction of samples that have each possible pair of values. Check that this is close to your joint probability table. Now change the program to only print out those samples which are consistent with your known value from the previous question (for example, samples where you are late for work). What fraction of these samples have each possible pair of values now? How does this compare to your answer to the previous question?
[Blackstone, 1765] Blackstone, W. (1765). Commentaries on the laws of England.