-

Spotted an error? Have comments?
Let us know!Get hands on with source code for the book.
Want to read offline?
Download the early-access PDF.
note: PDF layout/design is work in progress
Interlude: other inference methods
The core principle of model-based machine learning is that we have a model which contains our assumptions, and then apply an inference method to create an algorithm for training or prediction (see below for a visual reminder). So far in this book, we have developed a variety of different models, but in each case we have used the same inference method: expectation propagation. The fact that we have used the same inference method throughout underlines the point that inference methods are general and applicable to many different models.
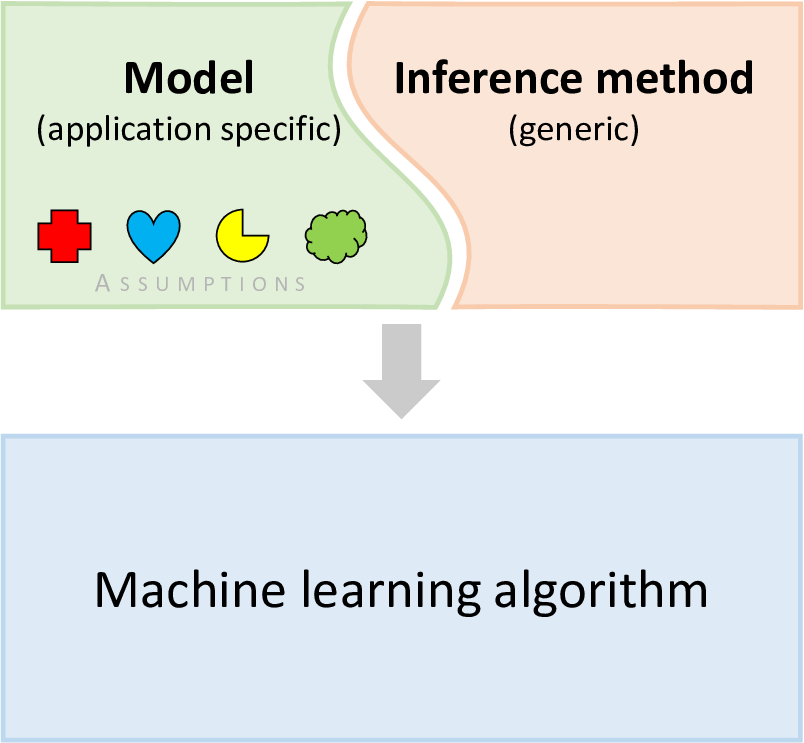
For any model, including the ones in this book, there is a choice of inference methods which can be applied. So, how do we choose which one to use? There are several factors which you might take into account:
- Computational cost - some inference methods may require more computation than others, particularly for certain kinds of model. This is usually a very important factor in the choice of inference method – it generally makes sense to pick the fastest method, unless it causes a significant reduction in accuracy.
- Accuracy - difference inference methods make different approximations which will affect the accuracy of the results. Depending on the application, it may be important to achieve higher accuracy, although this usually means that the algorithm will be more expensive to run. In general, there is a trade-off between accuracy and computational cost.
- Ease of implementation - some inference methods are easier to implement than others, or have standard implementations that can be easily picked up and used. This is an important factor early on in model development as often the aim is to get results quickly to validate the model. Later, it may make sense to have a customised inference method in order to achieve particular cost or accuracy targets.
- Flexibility - some inference methods can only be applied to certain kinds of model – for example, models which only contain discrete variables. If you want to use an inference method that cannot be applied to your model, then you can choose to modify the model – for example, replacing continuous variables with discrete ones. Alternatively, you can extend the inference method so that it can handle the non-compliant pieces of the model. One way to do this is to mix inference methods, so that a different, perhaps more expensive, inference method is used on the pieces of the model that the base method cannot handle.
We’ll now look at the inference methods available and assess them in terms of the above factors. Inference methods fall into a number of different families depending on the kind of output they produce, so we will explore each family in turn.
Distributions methods
Point methods
Sampling methods